
Sensitive data needs a new operating model because clean data is not necessarily safe nor fit-for-purpose
Enterprise data management has followed a simple logic: First, collect data. Then clean it. Then impute missing values. Then harmonize formats and standards. Once this work was done, the data was considered “ready” – ready for analytics, reporting, research, innovation, AI development, or commercial use.
This linear model was built for consistency, not for privacy. That distinction matters now more than ever.
In healthcare, pharma, finance, HR, public-sector data environments, and AI development, organizations are increasingly dealing with data that is not only valuable but sensitive. The most useful data is often the most granular, context-rich, and linkable. It contains the patterns that researchers, AI developers, and business teams need – but also the details that create privacy, legal, ethical, and reputational risk.
This changes the entire data-management question.The new question is: Can this data be safely transformed into a privacy-preserving, high-utility asset for this specific use case?
And increasingly: Can that transformation be repeated with data-utility optimizing amendments for the next use case?
The linear model worked reasonably well when the main problem was operational consistency. But it breaks down when data is sensitive. A dataset can be technically clean and still impossible to release. It can be beautifully harmonized and still too risky to share. It can be statistically rich and still legally unusable. It can be highly useful for one purpose and completely inappropriate for another.
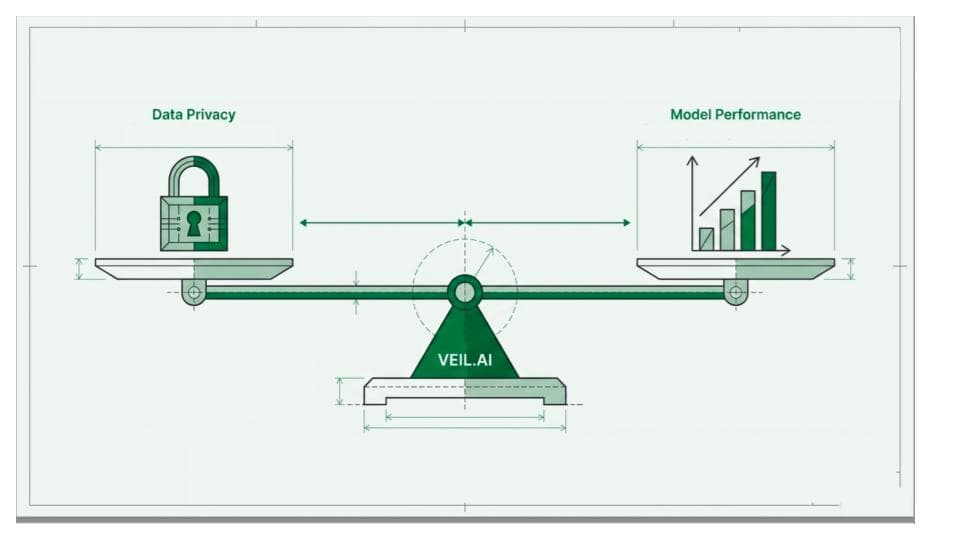
The white paper captures this shift clearly: privacy requirements now dictate how data must be transformed before it can be used, shared or commercialized. Organizations must optimize privacy and utility simultaneously; too little protection creates legal risk, while too much protection destroys analytical value.
The dilemma: utility versus privacy
Sensitive data creates a fundamental tension. Data is valuable because it is detailed. It contains relationships, outliers, time sequences, rare patterns, clinical signals, behavioral traces, and context. These are the features that make data useful for AI training, real-world evidence, financial analytics, product development, and research. But those same features can also make data identifiable, linkable, or sensitive.
At one extreme, raw or pseudonymized data may preserve maximum analytical utility, but it can carry significant privacy risk. At the other extreme, heavily suppressed or modified data may reduce privacy risk, but it may also become analytically useless.
The task is obviously not simply to remove identifiers but to find the right balance for a specific use case. AI training may require preservation of feature distributions, statistical relationships and minority patterns. Pharma real-world evidence may require preservation of treatment pathways, longitudinal structures and clinical outcomes. Commercial licensing may require repeatability, clear usage rights and defensible privacy evidence. Public or regulatory release may require strong anonymity thresholds, high transparency and conservative transformations.
There is no single universal version of “prepared data” anymore. There are only fit-for-purpose, privacy-optimized data products.
Privacy changes the order of operations
The biggest shift is operational.
In the old model, organizations prepared the data first and decided the uses later. In the new model, the intended use must come first. This reverses the data pipeline’s logic.
The intended use determines what must be preserved. The privacy criteria determine what must be protected. The utility requirements determine what transformations are acceptable. The governance context determines what evidence must be produced before the data can be released.
The deck describes this as a move from the legacy model – where the trigger was data collection and the goal was standardization, cleaning, and harmonization – to a new model where the trigger is the end-user requirement and the goal is a targeted balance between utility and privacy.Preprocessing is no longer a neutral technical activity. It is a strategic optimization process.
Some information may need to be generalized, suppressed, anonymized, or synthesized. Some variables may need to be privacy-engineered possibly quite heavily rather than released in original form. At the same time, certain variables or signals must be preserved at high fidelity, whereas others must be deliberately weakened to reduce disclosure risk.
The right answer depends on the purpose. A dataset for AI model development may need different transformations than a dataset for external research release, whereas regulatory authority may require different evidence than one for commercial licensing. A dataset for internal analytics may have different acceptable risk thresholds than those used across federated environments.
The flow is no longer linear; it is interlinked, iterative, and use-case-driven.
Why this matters for AI
AI makes the problem more urgent. AI systems need data that is rich, representative, and high-quality. Poor data creates poor models. Biased data creates biased models. Over-suppressed data weakens predictive power.
On the other hand, uncontrolled access to sensitive raw data creates serious privacy and governance risks. This is especially important in health data, clinical text, financial data, HR data, signal data, and other regulated domains.
The answer is not to stop using sensitive data or handing raw data over to every AI vendor, cloud platform or downstream user that asks for it. It is to transform sensitive data into safer, purpose-built assets that retain the utility required for the use case while meeting defined privacy criteria.
In practice, this means AI projects should not begin with a request to access the raw data. They should begin with the following question:
What data properties does the AI use case require, and how can we preserve those properties while protecting individuals and the organization?
That is a very different and a much more productive starting point.
From data liability to data products
Sensitive data is often treated as a liability: something difficult to access, hard to share, and risky to use. But with the right operating model, it can become a strategic asset. Advanced organizations will not merely share datasets. They will engineer governed, documented, reusable, and privacy-wise secure data products that include defined use rights, privacy criteria, utility metrics, transformation logic, versioning, documentation, auditability, and commercial terms.
This is where sensitive data becomes useful not only for compliance but also for AI development, research collaboration, commercial licensing, and innovation.
The deck frames this as a shift from compliance burden to strategic asset portfolio, with three key categories: compliant data releases, data for AI development, and monetization or commercialization. That shift is critical; privacy-preserving data management is no longer only a defensive compliance activity. It is becoming a core capability for data-driven organization.
Raw or pseudonymized sensitive data is often the most valuable asset an organization has, which should not be shared too broadly,early, or cheaply. Once raw or pseudonymized data is handed over, control is almost impossible to regain. The organization may lose control over privacy, reuse, competitive advantage, and even future monetization.
The wiser strategy is to protect the sensitive asset, define the intended use, control the anonymization strategy, verify anonymity, measure utility, and release only smaller, safer, smarter, and fit-for-purpose assets. This is the logic behind privacy-optimized data products.
The future is governed by transformation, not raw or pseudonymized data sharing.
Conclusion: privacy is now part of data architecture. Do not overengineer; the change can be done easily and gradually
The linear data pipeline was built for a world where consistency was the main problem but that has since changed.
In the new world, privacy requirements reshape how data must be prepared, transformed, documented, and released. Sensitive data cannot simply be cleaned and reused; it must be engineered for a specific purpose, with privacy and utility optimized together.
The organizations that understand this shift will be able to use sensitive data responsibly and competitively. These are the companies that will accelerate AI development, enable research, support regulated collaboration, and create new data products without losing control over their most valuable raw assets.
The organizations that do not will remain stuck between two bad options: data that is too risky to use, or data that is too degraded to matter.
The transition to privacy-optimized data and data products may sound like a major architectural shift, but the first step can be deliberately small. Start with one dataset and one high-value use case, e.g. AI training, research release, RWE analysis, test data, external collaboration, or data monetization.



