
We are living in the era of big data. But often large datasets contain sensitive personal information, where protecting privacy is of utmost importance. Three ways to ensure privacy in data that contains personal data are pseudonymization, anonymization, and the generation of synthetic data. These methods each differ in the way they handle privacy challenges and offer different levels of privacy protection while enabling valuable data analysis. What are the differences between these methods, and what are the use cases for them?
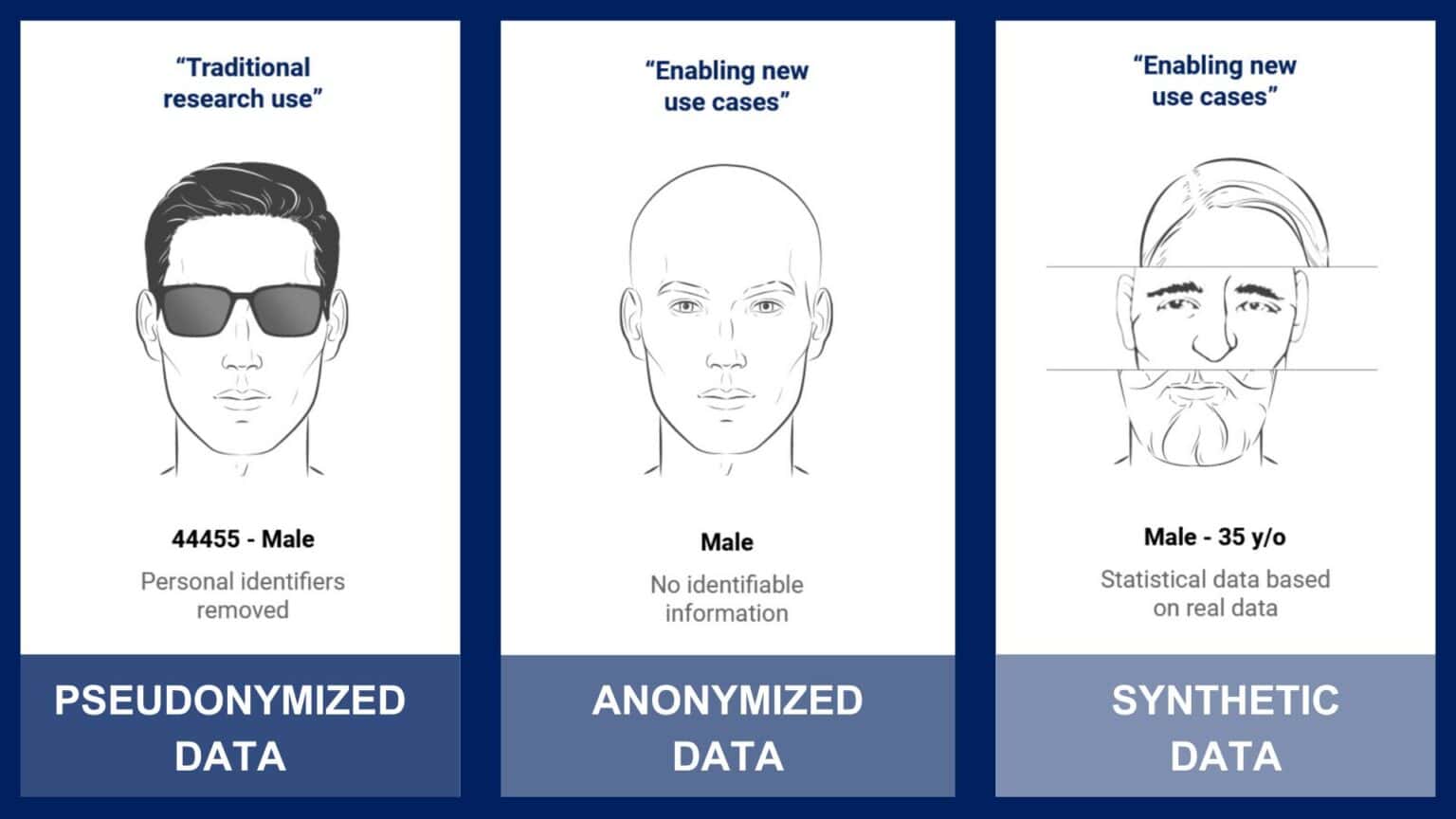
Pseudonymized Data
Pseudonymization means replacing directly identifiable information like names, addresses, or social security numbers with pseudonyms, or codes. These pseudonyms prevent direct identification of individuals in a dataset, but it is possible to access the key between real names and pseudonyms (for example to ask for additional information or return research results). This feature enables research that requires re-contact of study participants, like some types of clinical research.
Even if the key between direct identifiers and pseudonyms isn’t available, however, pseudonymized data itself still does not have a high level of privacy protection. This is because the data might contain a unique set of variables that can identify a single individual, even if direct identifiers are removed— the occupation ‘President’ is only held by one individual in a country, for example. When external information is available in combination with the pseudonymized data, it is even more likely that an individual could be re-identified.
This means that pseudonymized data is considered personal data under the European General Data Protection Regulation (GDPR) with the same strict set of privacy regulations as original data containing direct identifiers like names or addresses. In practice, this means that accessing or obtaining pseudonymized data can be time consuming, expensive, or even impossible.
Anonymized Data
Anonymization goes a step further by irreversibly transforming the data, removing both direct and indirect personal identifiers and making it practically impossible to re-identify real individuals from the data. This means that the data is no longer considered personal data and regulated under GDPR, and can be used for secondary purposes.
Legacy methods of anonymization can fulfill high privacy requirements, but they usually produce data that is low quality and not useful for downstream analysis. With VEIL.AI’s next-generation anonymization, however, quality is not sacrificed for privacy and anonymized data can be used safely for secondary purposes. Our next-generation anonymization has even been shown to reach the same conclusions as when original data is used in external control arms, but without strict privacy regulations.
This next-generation anonymized data can be used by all organizations utilizing sensitive data, and particularly:
Pharma & Diagnostics Companies
- Enabling transborder data collaborations— e.g. combining EU and US datasets
- Using anonymized RWD to create Real-World Evidence
- Reducing the cost of clinical trials by using anonymized data in external control arms
- Reusing existing RCT data for secondary purposes, increasing the value of the data
Hospitals
- Enabling broader utilization of health data in hospital data lakes
- Utilize anonymized patient data to develop algorithms for better treatments
- Collect and anonymize real-time streaming data from medical devices and wearables
Health Data Hubs & Regulators
- Quality assessment of anonymized data to evaluate and understand Real-World Data/ Real-World Evidence
Synthetic Data
Synthetic data is not a way of masking original data, but uses a set of rules or generative model to create artificial data that mimics the statistical properties and patterns of real data. While you might think at first that this gives high quality and security data, there are some pitfalls to synthetic data compared to anonymized data. First, synthetic data is often created with a generative model which might be biased in some unknown way, producing a dataset with cryptic bias. Second, because data is generated randomly, there’s a small chance information from a real data subject can be included. Due to these drawbacks, synthetic data is mainly suitable as test data for system development, not for downstream analysis and scientific applications.
Summary
| Method | Short Summary | Common Application |
|---|---|---|
| Pseudonymized Data | Replaces personal identifiers with pseudonyms, data remains indirectly identifiable | Medical research, privacy-compliant and highly regulated analysis |
| Anonymized Data | Irreversibly removes direct and indirect personal identifiers from real data sources | Practically the same applications as for pseudonymized data that do not require re-identification, including: – Enabling transborder data collaborations – Reducing clinical trial cost by use of RWD/RWE – Reusing RCT data for secondary purposes – Developing AI algorithms – Enabling utilization of health data in hospital data lakes |
| Synthetic Data | Artificial data generated based on a model or set of rules, mimicking real data properties | Software and IT systems development and testing |
Find out more about VEIL.AI’s Next-Generation Anonymization and Synthetic Data generation by getting in contact with us.